I was recently doing some clean-up on the content of the database-driven version of Benchmarks. One of the issues I was attempting to address was the presence of odd characters in the content. This is an attempt to explain how to discover what these characters are and how to find them.
Who are you?
An odd symbol or group of symbols where a character is expected is possibly a representation of a character that the web browser doesn’t know how to display or that has been corrupted by character conversion. Typically this occurs if the character set of the web page does not match the character set of the underlying text. For example: an em dash is represented differently in the character set table for UTF-8 than in that for Latin-1. As a result, while a web page encoded in UTF-8 will correctly display the UTF-8 em dash (—), a Latin-1 page will display a box ( or
or  ) or a seemingly random set of characters (—).
) or a seemingly random set of characters (—).
Some characters have entity references that will display correctly across character encodings. If we refer back to our example of the em dash, #8212 is the numeric entity reference for this character and will display correctly in either character set.
(Note: we should use UTF-8 encoding where possible … this should help mitigate character set conversion problems.)
Once you see an odd character it is fairly trivial to remove it from or replace it in the content. The problem with a corpus of text as large as Benchmarks is that it’s difficult to know by visual inspection if you have discovered all instances of the character in question.
Where are you?
Static text documents are fairly easily searched when trying to find the odd character, and a program such as Dreamweaver can make the searching that much easier by allowing you to copy the character in question into the “Find and Replace” window.
Things get a little more difficult when you’re talking about trying to find the character in a database. While the LOCATE function works fine for normal characters, occasionally a character can not be easily found using this method. In the case of the database-driven version of Benchmarks I was seeing a at the end of some text that did not lend itself well to searching using the LOCATE function. When a character such as this is encountered the first thing to do is try and figure out what the character is.
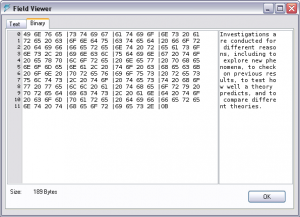
- Figure 1: MySQL Query Browser Text Viewer
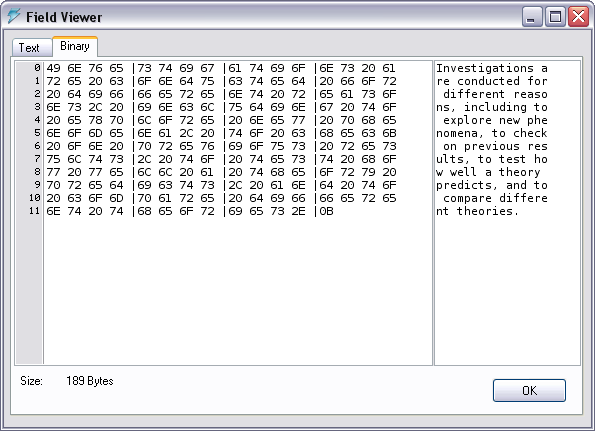
To determine the character I was seeing I opened up the MySQL Query Browser (QB) and accessed a record I knew to contain the character in question. The field containing the character was a TEXT field, making the process very easy since the QB has a handy feature to view the content of this type of field in a pop-up window (figure 1). Additionally, this pop-up window can display the content in either text or binary format. Binary format shows the text in a right-hand pane and the hexadecimal representation of that text in a left-hand pane. This makes character identification easier because we can reference the hexadecimal reference to the character rather than it’s visual appearance for identification.
If you do not have access to the QB but can run queries on the database you can manually convert the field in question to hexidecimal using the HEX() function (Query A).
SELECT field, hex(field) AS text2hex FROM table WHERE field REGEXP ‘[[.vertial-tab.]]’;
Query A
For the field I was reviewing the odd character appeared to be the last character in the field. Looking at the binary representation I notice that it had a character code of 0B. Looking up this code in an ASCII character chart reveals that it is a “vertial tab” … vertical tab? This isn’t a character typically typed in by an end user. Though the exact source is difficult to determine, most likely this was a translation error at some point during data entry or data migration.
Either way, the trick was to now find all instances of this character in the database. A vertical tab can’t be used as the needle in the LOCATE function, so I had to try something a little more advanced in the form of a regular expression. MySQL’s regular expression engine has capability to locate special characters. This particular character can be found either through a direct character reference (Query B) or a character class reference (Query C).
SELECT * FROM table WHERE field REGEXP '[[.vertical-tab.]]';Query B
SELECT * FROM table WHERE field REGEXP '[[:cntrl:]]';Query C
The latter query is possible because the vertical tab falls into a character class known as control characters. I prefer the former, however, for a known entity such as this because character class searching can result in unintentional matches (such as a tab or line break in this particular class).
Since this character can’t be used in the typical MySQL string functions I manually removed all instances of it. Though more advanced scripting could be used to automate the vertical tab removal I chose to manually edit the affected fields. The main reason was the relatively low number of affected fields.
This was a fairly rudimentary discussion of problems that can crop up with character encoding and conversion. See other posts related to these types of issues elsewhere.
References: